This post is about how I investigated an unresponsive web server and found a bug in a PHP application.
Background
One of the servers I maintained in a previous role was a small AWS EC2 instance that ran a LAMP stack. We didn’t receive particularly large volumes of traffic, so we could comfortably run several PHP applications on this server, including a couple of WordPress sites.
Another service that we ran on this was Sendy, an email newsletter application. We had a large mailing list, with recipients in the tens of thousands, and at this list size it wasn’t economical to use the popular SaaS offerings like SendGrid or Mailchimp. Sendy is self-hosted but uses Amazon SES for email delivery so it allowed us to frequently send newsletters to our entire list, at a very low cost.
On our first few send outs, however, I noticed that the web server would sometimes stop responding to web page requests for a few minutes at a time, even as the send out process continued humming in the background without issue. This was a problem because our newsletters had links (as their call-to-action) to pages on the WordPress sites running on this very server, and our analytics told us that a large number of our recipients clicked on those links (if they ever did) immediately after receiving our email. Meaning, our web server would go unresponsive just when we needed it the most, leading to frustrated users and a bad impression for our organization.
Investigation
During these downtimes, it was clear that it wasn’t the entire machine that was locking up. I could SSH into the host, and see the CPU utilization (with htop) elevated due to Sendy’s send out process, but not maxed out, and the emails continued to flow.
At first I thought it was an Apache httpd issue; perhaps we were receiving traffic spikes that somehow maxed out Apache’s capacity? But I checked with mod_status and Apache was doing just fine. I realized that despite the unresponsive websites, Apache continued to serve static assets (images) to email clients; therefore, the problem was with dynamic content—the problem was with PHP. Specifically, PHP-FPM; the send out was unaffected because it runs as a cron-triggered background process.
I turned to PHP-FPM’s status page and the slowlog. Correlating with Apache access logs, I found that the downtimes occurred whenever the FPM pool was maxed out with stalled requests to Sendy’s link-tracking code, l.php.
Our emails would often have many links besides the main call-to-action link, including standard contact addresses in the footer. The Apache logs showed that the email systems of certain recipients, apparently upon receiving our newsletter, and probably for some kind of pre-fetching mechanism, would hit all the links in the email simultaneously. These requests call Sendy’s l.php in our configuration. The logs looked like this:
2023-09-09 12:53:59+00:00 GET /l/1hi9Qg77DK/1CuxXjPRc8/cTXGD3B4eT HTTP/2.0
2023-09-09 12:53:59+00:00 GET /l/1hi9Qg77DK/eBbhS5pHLe/cTXGD3B4eT HTTP/2.0
2023-09-09 12:53:59+00:00 GET /l/1hi9Qg77DK/hrFTseSQjg/cTXGD3B4eT HTTP/2.0
2023-09-09 12:53:59+00:00 GET /l/1hi9Qg77DK/JSB4oi37ip/cTXGD3B4eT HTTP/2.0
2023-09-09 12:53:59+00:00 GET /l/1hi9Qg77DK/lFMil4Oat1/cTXGD3B4eT HTTP/2.0
2023-09-09 12:53:59+00:00 GET /l/1hi9Qg77DK/lqw7RW0pgs/cTXGD3B4eT HTTP/2.0
2023-09-09 12:53:59+00:00 GET /l/1hi9Qg77DK/NMPi5t21nH/cTXGD3B4eT HTTP/2.0
2023-09-09 12:53:59+00:00 GET /l/1hi9Qg77DK/sOyA0riZA7/cTXGD3B4eT HTTP/2.0
2023-09-09 12:53:59+00:00 GET /l/1hi9Qg77DK/TYlZ7636Ls/cTXGD3B4eT HTTP/2.0
Sendy does not document these request paths’ meaning, but I’ve deduced that the segments represent an email ID, a link ID, and a recipient ID; this explains why two of the segments are identical for all the requests in this batch.
Our FPM pool was configured with pm.max_children = 10, already double the default of 5 workers in the Linux distro we’re using, but even with these many workers the pool was still being clogged. I looked at the slowlog trace, which looked like this:
[09-Sep-2023 12:54:12] [pool www] pid 18633
script_filename = /var/www/sendy/l.php
[0x00007f605401c490] curl_exec() /var/www/sendy/l.php:258
[0x00007f605401c3f0] file_get_contents_curl() /var/www/sendy/l.php:112
[09-Sep-2023 12:54:12] [pool www] pid 19958
script_filename = /var/www/sendy/l.php
[0x00007f605401c490] curl_exec() /var/www/sendy/l.php:258
[0x00007f605401c3f0] file_get_contents_curl() /var/www/sendy/l.php:112
[09-Sep-2023 12:54:12] [pool www] pid 19960
script_filename = /var/www/sendy/l.php
[0x00007f605401c490] curl_exec() /var/www/sendy/l.php:258
[0x00007f605401c3f0] file_get_contents_curl() /var/www/sendy/l.php:112
The requests were stalling in a call to file_get_contents_curl() in l.php. Reading more of the file, I found that in some cases it does an HTTP request (curl) to Sendy’s email-opens-tracking code, t.php.
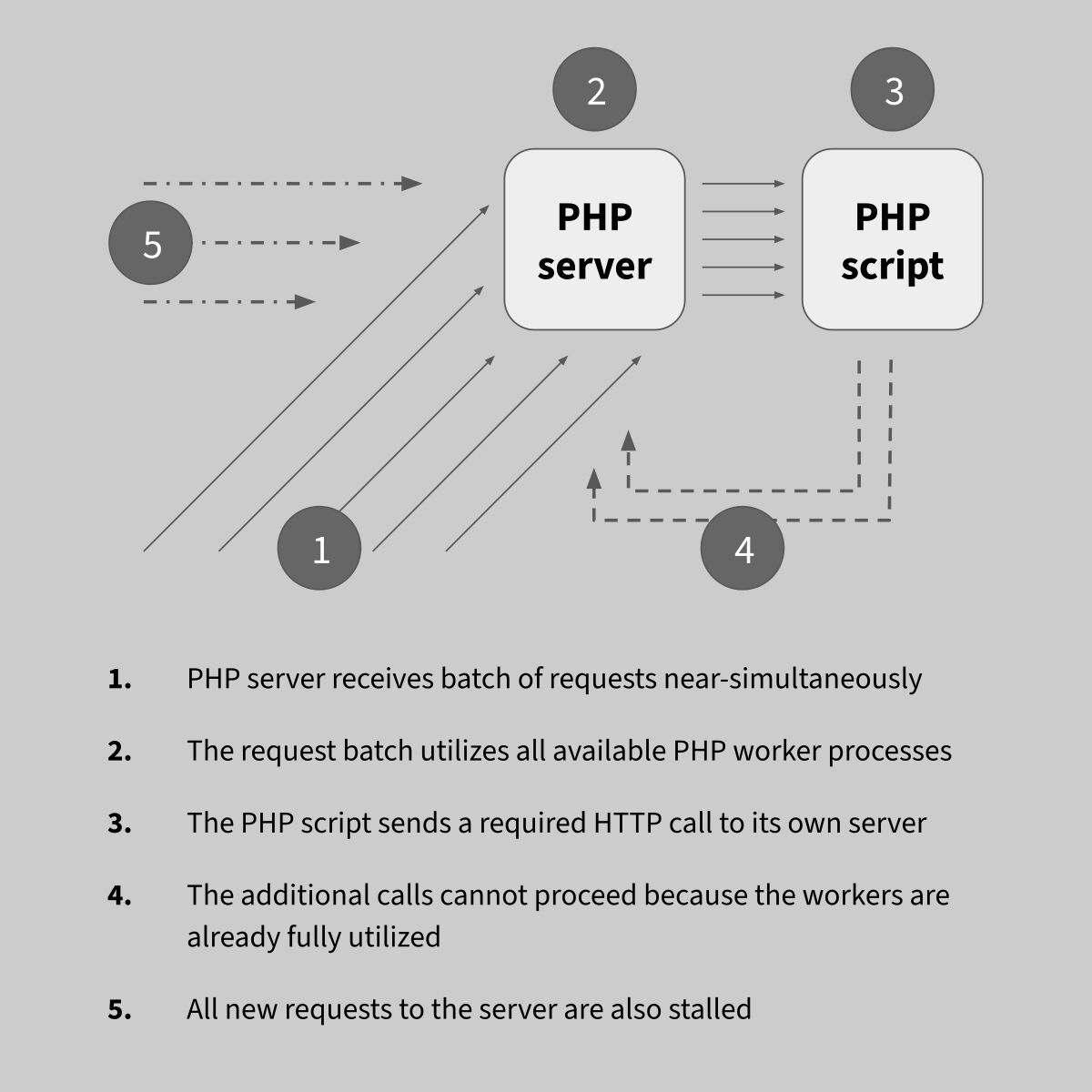
Here lies the issue: this dependence on a curl call is causing a deadlock. When the server gets a bunch of nearly simultaneous calls to the link-tracking script, enough in number to occupy all the FPM pool processes, the link-tracking script in turn sends calls to the opens-tracking script, at which point all the requests would hang because the pool is already 100% occupied with the ongoing link-tracking requests.
The curl call is not a good design, because it effectively amplifies the number of requests received by the system, and more importantly because it introduces this external variable to the reliability of the code.
It also leads to a potential denial-of-service issue: by crafting and sending a batch of HTTP calls to the link-tracking script, the PHP pool that Sendy runs on could be taken out for minutes at a time.
Resolution
We mitigated the issue on our server simply by setting pm.max_children much higher, so that the pool can accommodate the batches of calls without deadlocking. This was enough to prevent further occurrences of the incident for us, but we considered a further measure to put Sendy on an FPM pool of its own, so as not to affect the other PHP applications on the same host whenever it encounters this issue.
I reported my findings to Sendy’s developer, and also had an exchange with James Cridland, who explained to me what the curl call is for, confirmed my assessment of the design weakness, and suggested a quicker fix—adding a short timeout to the curl calls.
Sendy published the quick fix for the issue in version 6.0.7.2, released in September 2023.